Matrix Multiplication Loop Interchange
Unfortunately life is rarely this simple. Apart from locality of memory there is also compiler optimisation.

Algorithms Chapter 3 With Questionanswer Animations Chapter Summary
The simplest form of multidimensional array is the two-dimensional array.

Matrix multiplication loop interchange. The number of capacity misses clearly depends on the dimension parameters. The first example uses sequential execution for all loops. In this C matrix multiplication example within the C nested for loop we multiplied the subarr1 matrix with subarr2 and assigned it to multiplication.
The multiplication of Matrix M1 and M2 24 224 36 108 49 -16 11 9 273 Create Python Matrix using Arrays from Python Numpy package. Add multi-threading to each function in MatMulcpp using OpenMP Work-Sharing directives. Run the matrix multiplication with an input matrix size of 256.
Repeat the 4 solutions for both optimization level O1 and optimization level O2 and record the execution times for the 9 runs. K for j0. This means it can be rewritten as.
What order should the loops be in to get the best performance. In the matrix multiplication code we encountered a non-unit stride and were able to eliminate it with a quick interchange of the loops. J c i j c i j a i k b k j.
They illustrate more complex policy examples and show additional RAJA kernel features. The first for loop within this C If statement uses the temp variable to interchange the matrix diagonal. Run another Memory Access Patterns analysis in the CLI.
Now I guess I have to prove it so add this code to the bottom so it will compare my code to the usual Mathworks matrix multiplication method and show that there is no difference. Write a C Program to Multiply two Matrixes with an example. M n p and the size of the cache.
Compiling and running the new code will result in 13-second runtime which is a significant 20x improvement over original 26 seconds. To declare a two-dimensional integer array of size xy you would write something as follows For example suppose number C Language Samples Separate Chaining Internal method to test if a positive number is. You can reorder the loops above eg for i for j for k as shown above or they could be in another order like for j for i for k.
For int k 0. Here is the source code of the Java Program to Interchange any two Rows Columns in the given Matrix. R R A I K B K J.
Iinumt for k0. K cij cij aikbkj. Next we used cout to print the multiplication matrix items.
To work with Numpy you need to install it first. If we are using OpenMP we can use pragma omp for and with static scheduling as work can be equally split. Matrix multiplication leads to a new matrix by multiplying 2 matrices.
With multi-threading disabled interchange the two innermost iterations in the matmul function. The matrix multiplication kernel variations described in this section use execution policies to express the outer row and col loops as well as the inner dot product loop using the RAJA kernel interface. A key one for vector and matrix operations is loop unrolling.
The python library Numpy helps to deal with arrays. Often you find some mix of variables with unit and non-unit strides in which case interchanging the loops moves the damage around but doesnt make it go away. Numpy processes an array a little faster in comparison to the list.
You can see in this inner loop i and j do not change. The two inner loops read all p by n elements of B and access the same p elements in a row of A repeatedly and write one row of n elements of C. In ComputeV4 it is possible to interchange the loop which iterates over all possible displacements and the loop which scans over the 4 4 block itself.
C I J R. As in naive matrix multiplication the writes and reads are into a different array we can parallelize the outer loop. Do it the usual way with matrix multiplication instead of for loops.
Which order give the best performance. The matrix multiplication kernel variations described in this section use execution policies to express the outer row and col loops as well as the inner dot product loop using the RAJA kernel interface. Later traverse the matrix once again and replace all elements with assigned value to 0.
Advixe-cl --mark-up-loops --selectmultiplycc21 --project-dirusertestmatrix_project -- usertestmatrix advixe-cl --collectmap --project-dirusertestmatrix_project -- usertestmatrix. If the displacement loop is the outer one the 4 4 block of the actual image and a 12 4 region of the previous image must be kept in foreground if we work row-wise or column-wise to avoid duplicate transfers from background memory to the data-path. To verify the new access patterns.
In this C matrix multiplication example we placed the cout.
Https Hal Archives Ouvertes Fr Hal 01409286 Document

Solved Project 10 Description Write Program Opens Input File Contains One Sets Code Followed One Q37096219

Parallel Algorithms For Array Processors Ppt Video Online Download

Java Program To Find The Sum Of The Matrix Upper Triangle

Java Program To Find Sum Of Each Matrix Column
![]()
Go Program To Transpose A Matrix

Cs61c Fall 2012 Lab 7
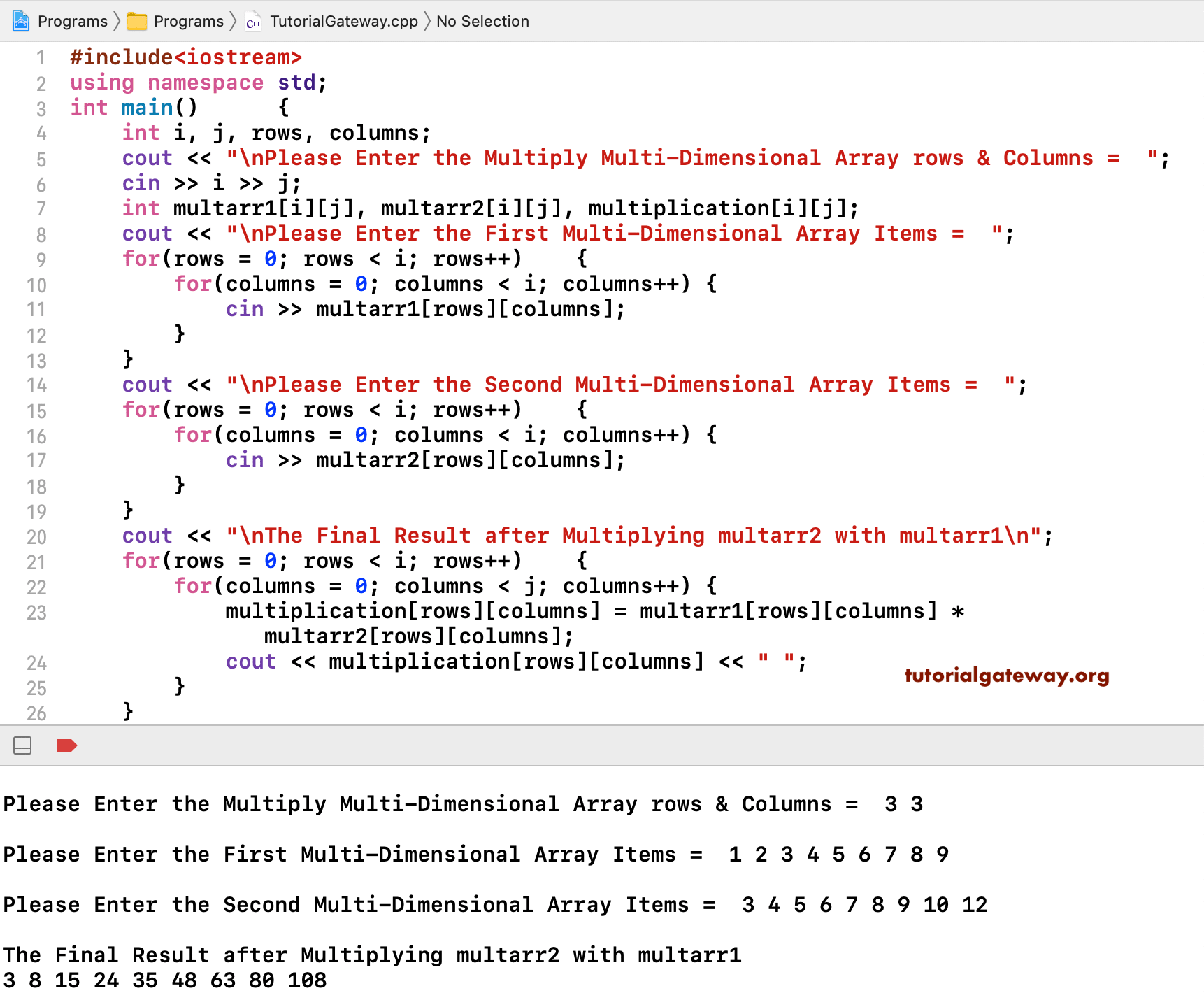
C Program To Multiply Two Matrixes
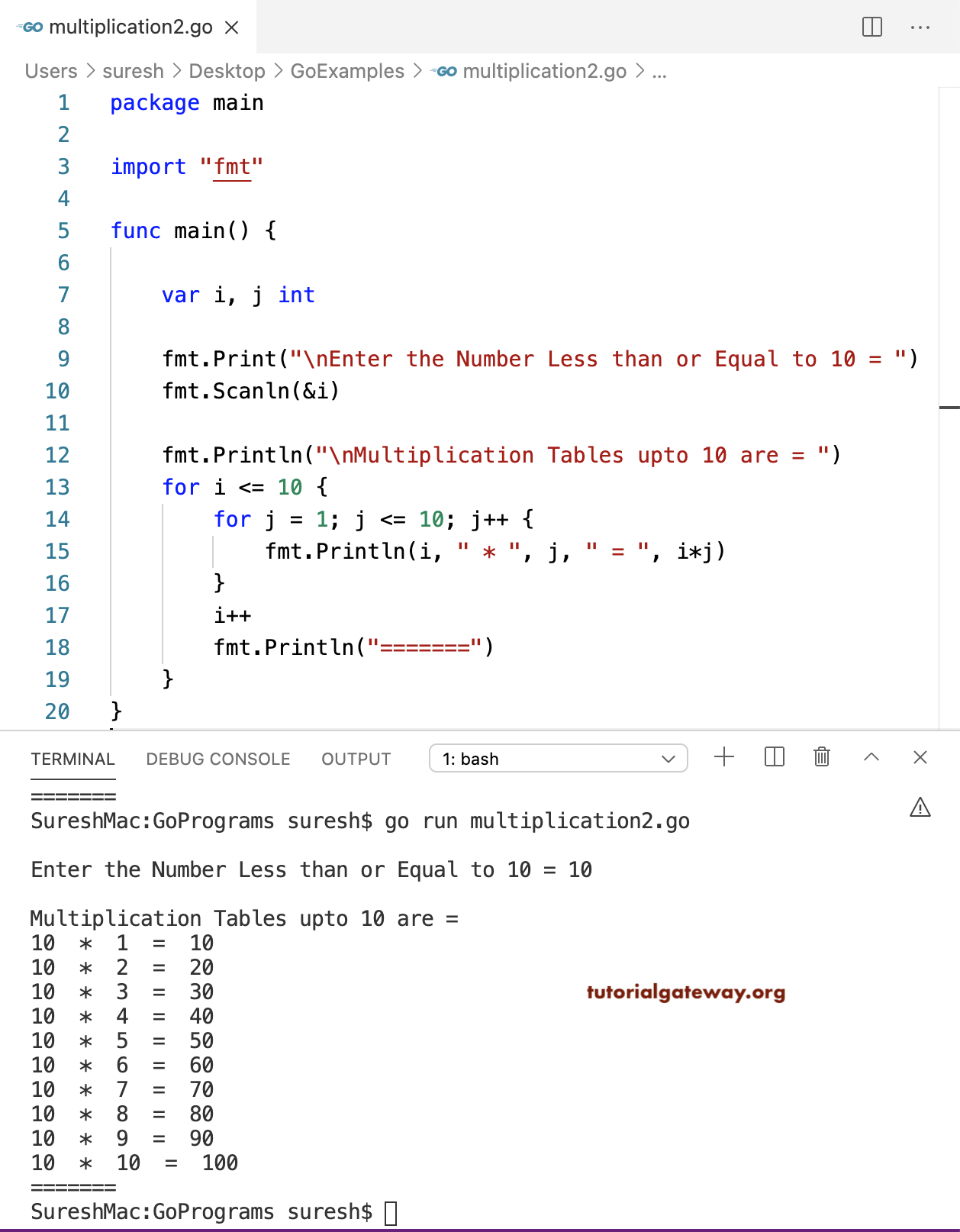
Go Program To Print Multiplication Table

Cs61c Fall 2012 Lab 7

Tune Algorithms

Tune Algorithms

Java Program To Interchange Any Two Rows And Columns In The Given Matrix Studytonight

Java Program To Find Matrix Is A Symmetric Matrix
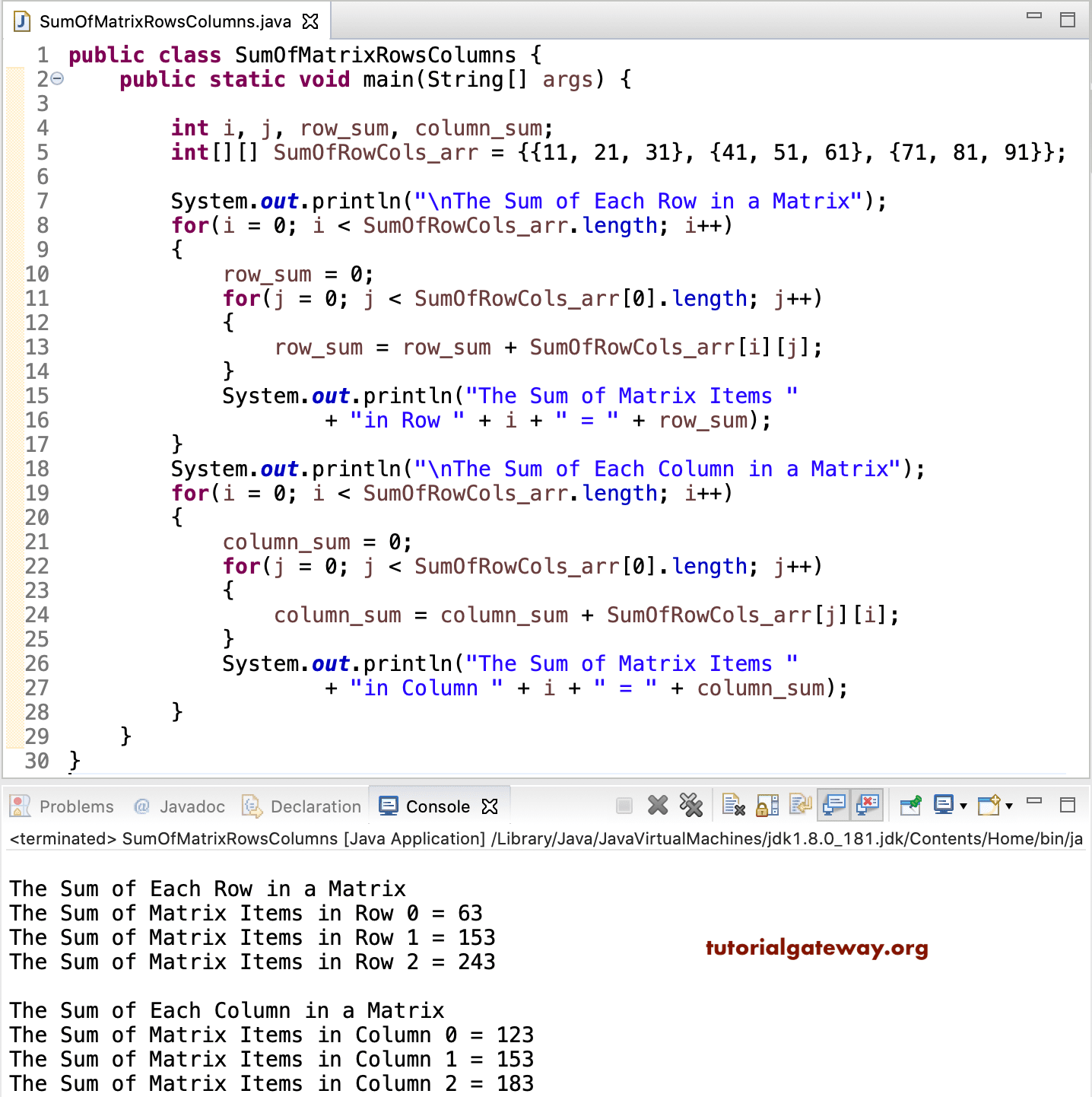
Java Program To Find Sum Of Matrix Rows And Column
Https Hal Archives Ouvertes Fr Hal 01409286 Document

2 D Array Ppt Download

Using The Iteration Space Visualizer In Loop Parallelization Yijun Yu Ppt Download
Algorithms Chapter 3 With Questionanswer Animations Chapter Summary