Matrix Multiplication Using Simd
Given M as its four constituent. This application note describes the multiplication of two matrices using Streaming SIMD Extensions.

Pseudo Code Of Parallel Matrix Multiplication On Epuma Download Scientific Diagram
The templated code below implements the innermost loops that calculate a patch of size regA x regB in matrix C.
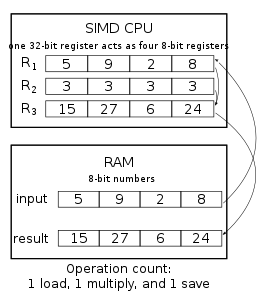
Matrix multiplication using simd. February 5 2015. Since the columns is the multiples of 4 naturally I hope to write more efficient SIMD codes than auto-vectorization. Here were encoding a kernel to compute a result with M rows and N columns.
In Section 43 you can find a ready-to-run example for 4x4 matrix multiplication. For int k 0. __m128 m1 _mm_loadu_ps.
However the estimated. OK for reference doing 100 multiplications with n. If youre using Metal performance shaders you will benefit from SIMD group scope matrix multiplies to accelerate not only matrix multiplication but also CNN convolutions.
The author gives the following code snippet. Suppose we want to calculate a product between a 44 matrix M and a 4-element vector v. In my previous post I tried to explain how to use SIMD instructions for a really simple and artificial example.
At every PE_i do the following n times. In this post were using gccs auto-vectorization. SSE instructions can be executed by using SIMD intrinsics or inline assembly.
We compare 3 versions. Let A and B be two matrices with size n times n and C be the result matrix. K 4 __m128 v _mm_loadu_ps.
Time complexity of matrix multiplication is On3 using normal matrix multiplication. Just adding numbers in two vectors togetherIn this post Id like to take this just a little bit further and talk about matrix multiplication. Depending on the inner loop i A matrix lines are loaded to fast memory.
Initialize C vector to in all PEs. In multi-threading instead of. With matrices A B and computing C A B.
__m128 m0 _mm_loadu_ps. And Strassen algorithm improves it and its time complexity is On28074. Multi-threading can be done to improve it.
After giving it some thought I realized I could do the calculation for the resulting matrix row-by-row instead by lining up the registers something like this each row is one SIMD register and each column is the x y z w parts. Each multiplication requires a prefetch of y vector and x vector to fast memory. Multiplication of matrix does take time surely.
But Is there any way to improve the performance of matrix multiplication using the normal method. Matrix multiplication is not the best motivating example for the unique fea-tures of SIMD types. I am currently reading an article on github about performance optimisation using Clangs extended vector syntax.
Distribute ith row of matrix A and ith column of matrix B to PE_i where 1 leq i leq n. The sizes of matrix of 4rows 4n columns and that of vector is 4n. The reason this example is important is because matrixmultiplication is a relatively simple algorithm though hard to implement withmaximum efficiency and a well-known and well-researched problem.
Matrix multiplication for arbitrary sizes can be performed using MPS matrix multiplication. A_00 B_00 A_00 B_01 A_01 B_10 A_01 B_11 A_02 B_20 A_02 B_21 A_03 B_30 A_03 B_31. Void Matrix_Vector_Mult_haddfloat vector float matrix int vectorLength float results __m128 s0 _mm_set1_ps00f s1 _mm_set1_ps00f s2 _mm_set1_ps00f s3 _mm_set1_ps00f.
Matrix-Matrix-Multiplication Benchmark While the SAXPY is great for its simplicity and assembly analysis the real performance gain of using SIMD intrinsics can be shown by tackling compute bound problems. Matrix vector multiplication m number of slow memory references read x1n read y1n write y1n number of elements in one row of A num A rows. AP-929 Streaming SIMD Extensions - Matrix Multiplication.
Hi everyone I would like to optimize matrix-vector multiplication using SIMD. Lets first look at matrix vector multiplication. The standard approach to computing Mv using SIMD instructions boils down to taking a linear combination of the four column vectors a b c and d using standard SIMD componentwise addition multiplication and broadcast shuffles.
Matrix Multiplication using SIMD vectors in C. The classical problem being the Matrix-Matrix-Multiplication.
Simd Wikiwand

Parallel Matrix Multiplication C Parallel Processing By Roshan Alwis Tech Vision Medium

6 Element Double Precision Vector Matrix Vector Multiply In Avx Stack Overflow
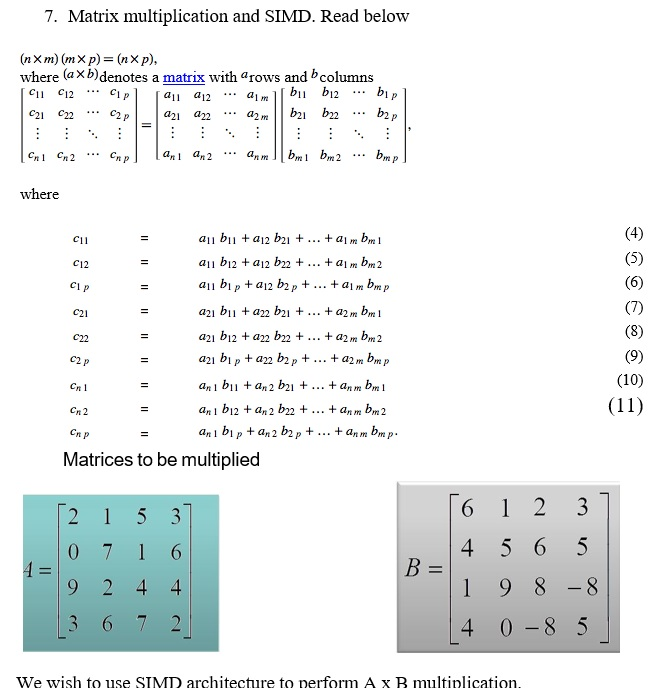
Solved 7 Matrix Multiplication And Simd Read Below N X Chegg Com
Optimizing C Code With Neon Intrinsics

Parallel Algorithms For Array Processors Ppt Video Online Download

Sebastian Aaltonen On Twitter New Metal A14 Features Primitive Id Barycentric Coordinates All You Need For Your G Buffer Anyways Also Simd Subgroup Operations And Intrinsics For 4x4 8x8 Group Multiplications This Is Much Better Than Those High

The Matrix Multiplication With Simd Download Scientific Diagram
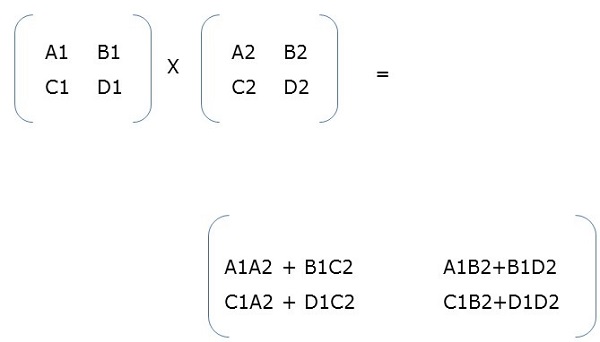
Parallel Algorithm Matrix Multiplication Tutorialspoint

Saral Gyan Simd Matrix Multiplication Algorithm Youtube

Parallel Algorithms For Array Processors Motivation For Simd

Pdf An Optimized Matrix Multiplication On Armv7 Architecture Semantic Scholar
Simd Single Instruction Multiple Data

Simd Single Instruction Multiple Data

Github Hananabilabd Simd Matrix Multiplication
Matrix Multiplication With A Hypercube Algorithm On Multi Core Processor Cluster

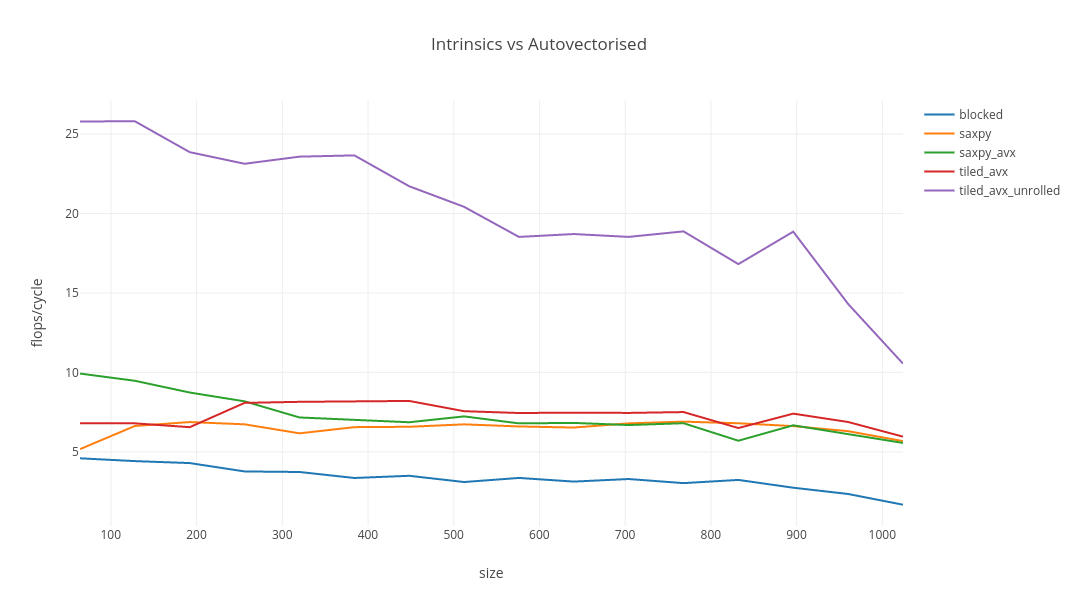
Matrix Multiplication Revisited Richard Startin S Blog
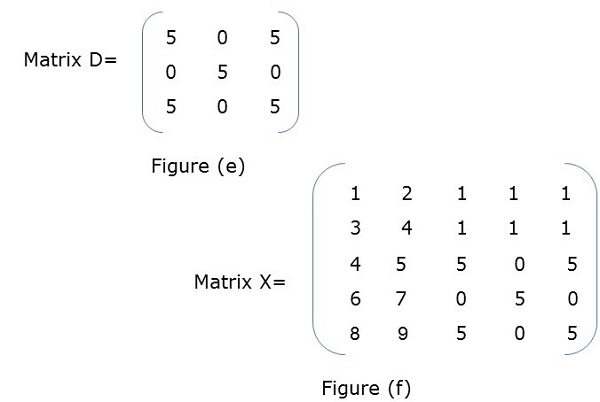
Parallel Algorithm Matrix Multiplication Tutorialspoint
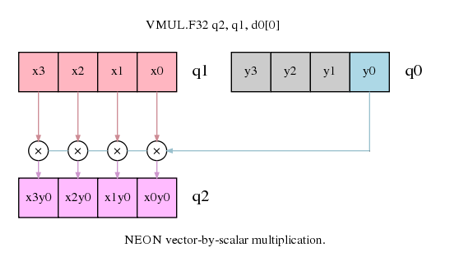
Coding For Neon Part 3 Matrix Multiplication Processors Blog Processors Arm Community