Multiply Vector By Matrix Cuda
If you want to know how to use registers instead of shared memory then. My last CUDA C post covered the mechanics of using shared memory including static and dynamic allocation.

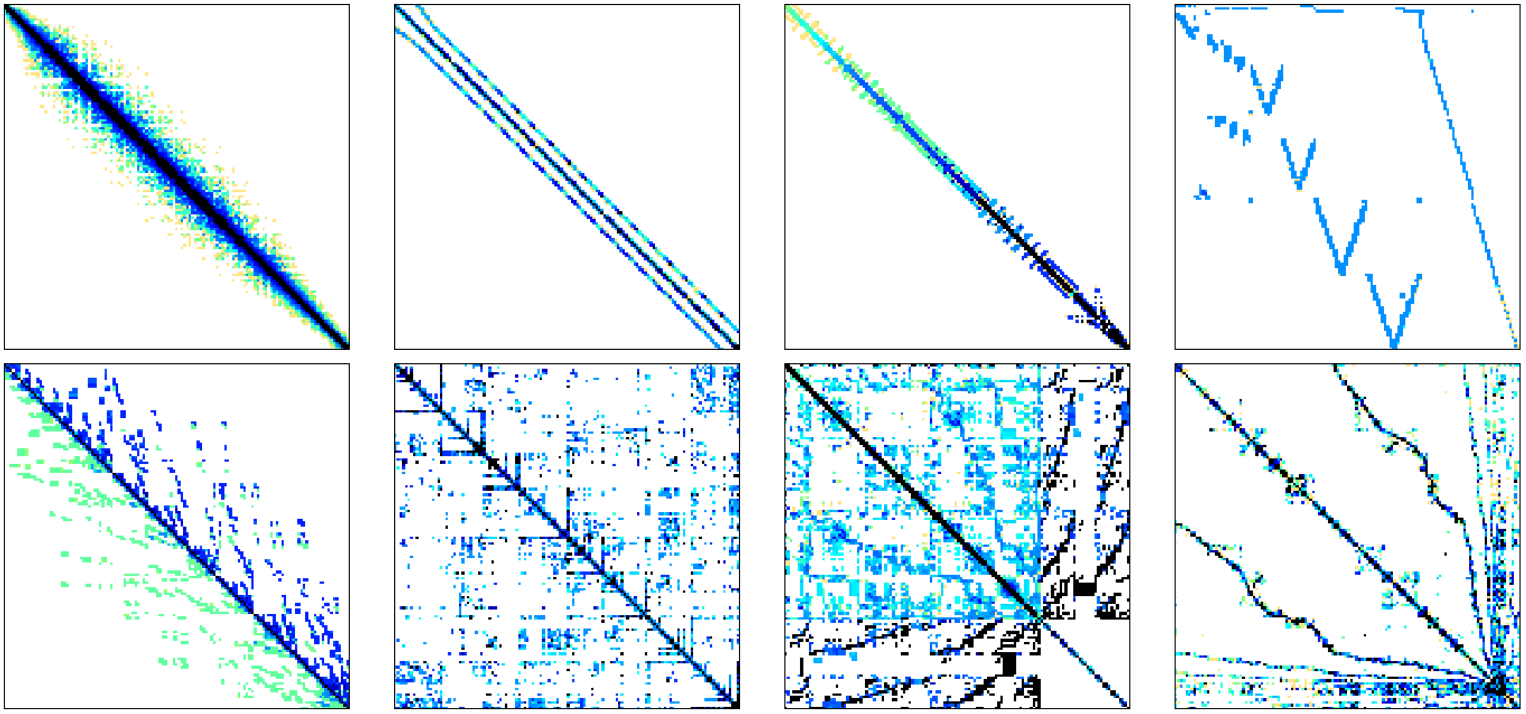
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium
GPUProgramming with CUDA JSC 24.
Multiply vector by matrix cuda. Refer to vmppdf for a detailed paper describing the algorithms and testing suite. 1 Examples of Cuda code 1 The dot product 2 Matrixvector multiplication 3 Sparse matrix multiplication 4 Global reduction Computing y ax y with a Serial Loop. Matrix multiplication between a IxJ matrix d_M and JxK matrix d_N produces a matrix d_P with dimensions IxK.
Specifically I will optimize a matrix transpose to show how to use shared memory to reorder strided global memory accesses into coalesced accesses. E cient Sparse Matrix-Vector Multiplication on CUDA Nathan Bell and Michael Garlandy December 11 2008 Abstract The massive parallelism of graphics processing units GPUs o ers tremendous performance in many high-performance computing applications. Our computation amounted to multiplying together the vector and that column as shown in Figure13.
Contents 1 Matrix Multiplication3. Its difficult to tell what is being asked here. If both arguments are at least 1-dimensional and at least one argument is N-dimensional where N 2 then a batched matrix multiply.
CUDA C program for matrix Multiplication using Sharednon Shared memory Posted by Unknown at 0907 23 comments. If the first argument is 1-dimensional and the second argument is 2-dimensional a 1 is prepended to its dimension for the purpose of the matrix multiply. Matrix Multiplication with CUDA A basic introduction to the CUDA programming model Robert Hochberg August 11 2012.
You could just let different parts of the vector multiplication run on different coresprocessesmagic. The goal of this project is to create a fast and efficient matrix-vector multiplication kernel for GPU computing in CUDA C. While dense linear algebra readily maps to such platforms.
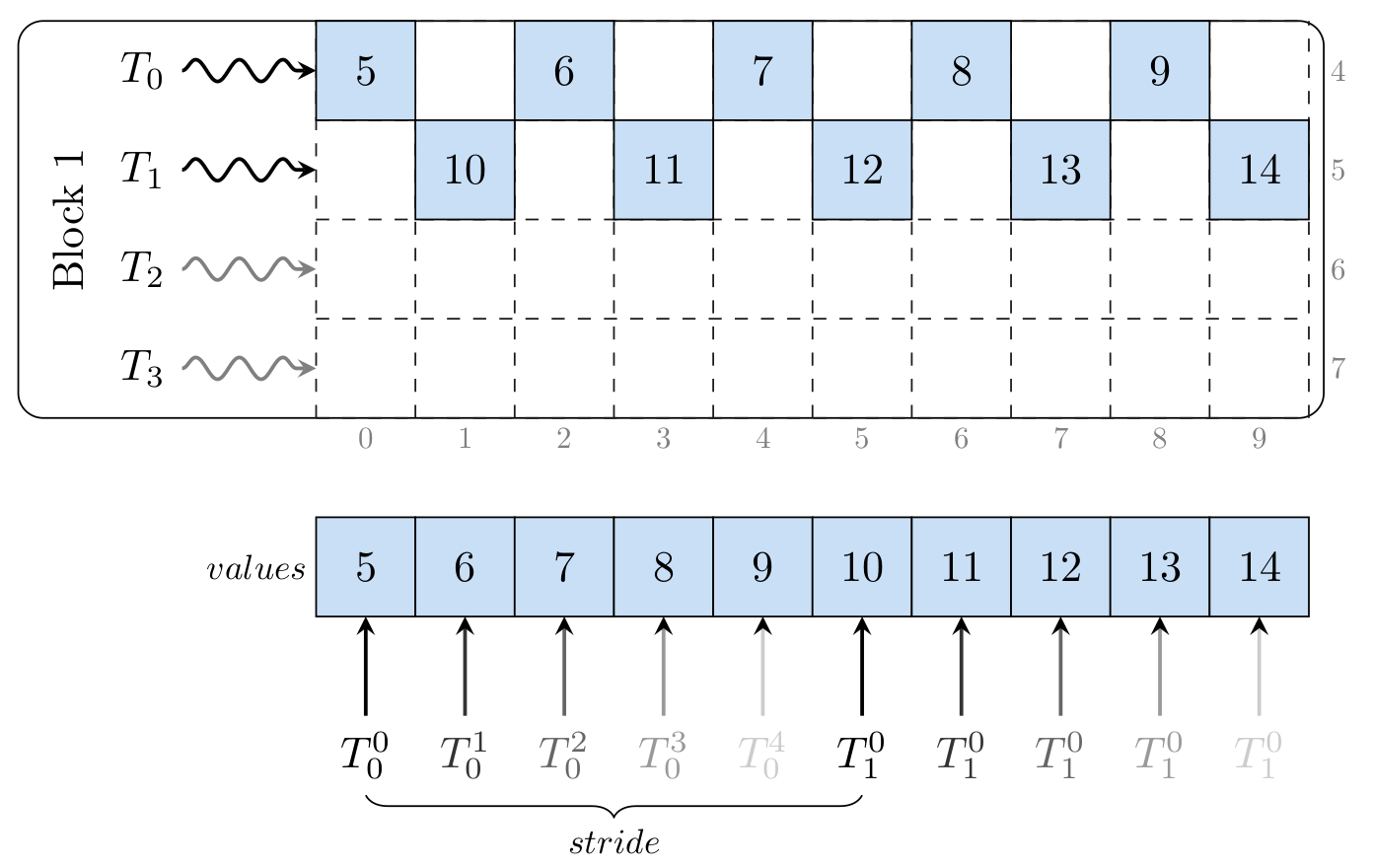
This question is ambiguous vague incomplete overly broad or rhetorical and cannot be reasonably answered in its current form. April 2017 Slide 15 Matrix-matrix multiplication with blocks Ckl i1 N Aki Bil C kl i1 N2 Aki Bil iN2 1 N Aki Bil For each element Set result to zero For each pair of blocks Copy data Do partial sum Add result of partial sum to total. Matrix-Vector Multiplication Using Shared and Coalesced Memory Access.
Viewed 11k times 4. For matrix-matrix multiplication matrixMul in SDK uses shared memory but only works for specific dimension. - Convert the multiplication Vector x to a 2D texture - Pointwise multiply N Diagonal textures with x texuture - Add the N resulting matrices to form a 2D texuture - unwrap the 2D texture for the final answer Matrix-Vector Operations zTechnique 3.
Multiplying paths of length 1 from C by paths of length 3 to J. After the matrix multiply the prepended dimension is removed. The formula used to calculate elements of d_P is.
In the previous post weve discussed sparse matrix-vector multiplication. Vector Addition in CUDA CUDA CC program for Vector Addition Sobel Filter implementation in C. Compile and Run CUDA CC Programs.
Obvious way to implement our parallel matrix multiplication in CUDA is to let each thread do a vector-vector multiplication ie. How can multiply vector by a matrix using CUDA c closed Ask Question Asked 8 years 6 months ago. Active 7 years 4 months ago.
You can try to extend matrixMul in SDK to arbitrary dimension. For matrix-vector multiplication you can look at reduction example in SDK. If the first argument is 2-dimensional and the second argument is 1-dimensional the matrix-vector product is returned.
In this post I will show some of the performance gains achievable using shared memory. Block Sparse Matrix-Vector Multiplication with CUDA. Sparse Matrices Create a texture lookup scheme Matrix Operations in CUDA Take 2.
Each element in C matrix will be calculated by a. It was shown that its possible to. By which i mean the matrix multiplication rule is line by column loosely translated and then you just let the multiplication of line1-by-column1 run on the first core and line2-by-column1 on the next and so forth.

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Hierarchical Matrix Operations On Gpus Matrix Vector Multiplication And Compression

Hierarchical Matrix Operations On Gpus Matrix Vector Multiplication And Compression

Sparse Matrix Vector Multiplication And Csr Sparse Matrix Storage Format Download Scientific Diagram

Convert Vector Summation Into Matrix Multiplication Youtube

Pin On Useful Links

Word2vec Tutorial The Skip Gram Model Tutorial Machine Learning Learning
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Matrix And Vector Multiplication Programmer Sought

Figure 1 From Automatically Generating And Tuning Gpu Code For Sparse Matrix Vector Multiplication From A High Level Representation Semantic Scholar

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

4 3 1 Transpose Matrix Vector Multiplication Youtube

Gpu Accelerated Sparse Matrix Vector Multiplication And Sparse Matrix Transpose Vector Multiplication Tao 2015 Concurrency And Computation Practice And Experience Wiley Online Library
Cuda Matrix Vector Multiplication Transpose Kernel Cu At Master Uysalere Cuda Matrix Vector Multiplication Github

Pseudocode Of The Csr Based Spmv Download Scientific Diagram

2 Vector Add Dive Into Deep Learning Compiler 0 1 Documentation
A Provide The Appropriate Pseudo Code For Exploit Chegg Com
