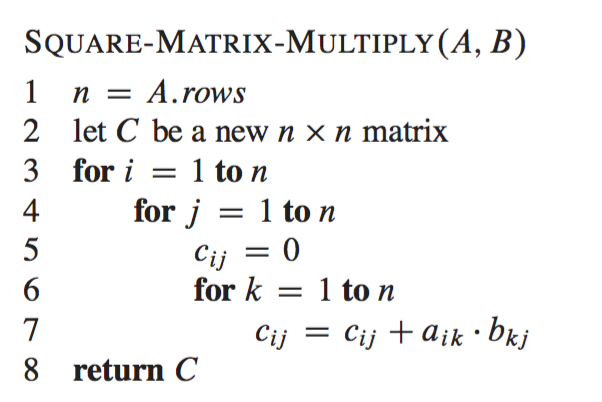Matrix Multiplication Loops Performance
This is a collection of observations on getting best performance with sparse matrices in Armadillo. Cache cant store all of the cache lines for one column of matrix B.
Pin On Stats Ml

It performs element-wise multiplication of two vectors of complex numbers and assigns the results back to the first.

Matrix multiplication loops performance. Center_points f 2end-12. For special cases such as sparse matrices you can write specialized algorithms. This can improve performance by a factor of 3 on a 4 core CPU.
Another thing you can do to improve performance is to multi-thread the multiplication. Perform a calculation well see why this is important later Reuse of data. Matrix-Matrix Multiply ddot form do i1n do j1n do k1n cij cij aik bkj Like transpose but two new features.
F_smoothed zeros 1f_length. All the timings in this article were generated using Armadillo version 8500. This version adds a number of substantial optimisations for sparse matrix operations in some cases speeding things up by as much as two orders of magnitude.
For j 1smoothing_loops. There are six memory operations four loads and two stores and six floating-point operations two additions and four multiplications. For matrix multiplication the simple On3 algorithm properly optimized with the tricks above are often faster than the sub-cubic ones for reasonable matrix sizes but sometimes they win.
Cache Analysis of Looping Code 9 Suppose that n is sufficiently largeLet B be the size of a cache line. If the CPU does not have enough registers the compiler will schedule extra loads and stores to spill the registers into stack slots which will make the loop run slower than a smaller blocked loop. If the matrices do not both fit into the cache some data will invariably end up loaded multiple times.
To compute the matrix multiplication correctly the loop order doesnt matter. F input_y. Matrix multiplication is like many other codes in that it can be limited by memory bandwidth and that more registers can help the compiler and programmer reduce the need for memory bandwidth.
Storing the arrays row-by-row or column-by-column does not solve the problem because both rows and columns are used in every iteration of the loop. If method 0. Optimizing the data cache performance ------- Taking advantage of locality in matrix multiplication When we dealing with multiple arrays with some arrays accessed by rows and some by columns.
However the order in which we choose to access the elements of the matrices can have a large impact on performance. Computing each element of matrix C incurs Θn cache misses. No temporal locality on matrix B.
F_length length f. Computing an element of matrix C involves ΘnB cache misses for matrix A and Θn cache misses for matrix B. Caches perform better more cache hits fewer cache misses when memory accesses exhibit spatial and temporal locality.
Lastly you might consider using float or double You might think int would be faster however that is not always the case as floating point operations can be more heavily optimised both in hardware and the compiler. Smoothing_matrix smooth_1 1end-21end-4 eye f_lengthf_length-2. N2 data used for n3 operations.
Smooth_1 diag ones f_length1-2. Each row vector on the left matrix is repeatedly processed taken into successive columns of the right matrix. Matrix multiplication exhaustively processes elements from both matrices.
C Code That Constructs A Matrix Multiplication And Transforms It With Download Scientific Diagram
Proposed 4 4 Matrix Multiplication Method A Partitioning Of A 4 Download Scientific Diagram

Matrix Multiplication An Overview Sciencedirect Topics

Matrix Multiplication In Python We Often Encounter Data Arranged Into By Anna Scott Analytics Vidhya Medium
Fortran Matrix Multiplication Performance In Different Optimization Stack Overflow

Matrix Multiplication With A Hypercube Algorithm On Multi Core Processor Cluster

Matrix Multiplication In C Applying Transformations To Images Codeproject
Tiled Matrix Multiplication A 5 Loop Tiled Matrix Multiplication And Download Scientific Diagram

Matrix Multiplication Algorithm Wikiwand

Toward An Optimal Matrix Multiplication Algorithm Kilichbek Haydarov

Multiplying Matrices Article Matrices Khan Academy
Parallel Matrix Multiplication C Parallel Processing By Roshan Alwis Tech Vision Medium

Communication Costs Of Strassen S Matrix Multiplication February 2014 Communications Of The Acm

Pseudocode For Matrix Multiplication Download Scientific Diagram

Toward An Optimal Matrix Multiplication Algorithm Kilichbek Haydarov

Toward An Optimal Matrix Multiplication Algorithm Kilichbek Haydarov

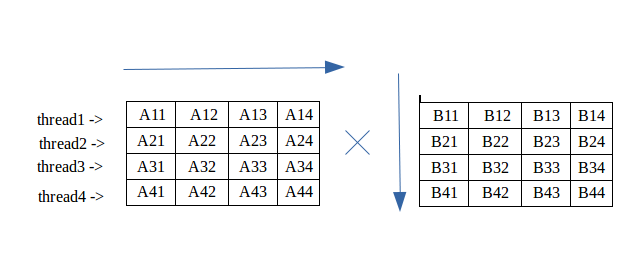
Multiplication Of Matrix Using Threads Geeksforgeeks
Understanding Matrix Multiplication On A Weight Stationary Systolic Architecture Telesens

Matrix Multiplication Using The Divide And Conquer Paradigm