Vector Matrix Multiplication In Cuda
Shared. It was shown that its possible to.

A Distribution Of A Matrix And A Vector Across 8 Mpi Processes Petsc Download Scientific Diagram
This provides an understanding of the different sparse matrix storage formats and their impacts on performance.
Vector matrix multiplication in cuda. A d_P element calculated by a thread is in blockIdxyblockDimythreadIdxy row and blockIdxxblockDimxthreadIdxx column. MatrixMulSh float Md float Nd float Pd const int WIDTH. __shared__ float Mds TILE_WIDTH.
Each element in C matrix will be calculated by a. You can try to extend matrixMul in SDK to arbitrary dimension. For matrix-matrix multiplication matrixMul in SDK uses shared memory but only works for specific dimension.
I yi alphaxi yi Invoke serial SAXPY kernel. The formula used to calculate elements of d_P is. This is an implementation of a parallel sparse-matrix vector multiplication algorithm on the GPU.
A search or a quick browse of recent CUDA questions will reveal at least three questions about this subject inlcuding code. Obvious way to implement our parallel matrix multiplication in CUDA is to let each thread do a vector-vector multiplication ie. For matrix-vector multiplication you can look at reduction example in SDK.
Block Sparse Matrix-Vector Multiplication with CUDA. In iterative methods for solving sparse linear systems and eigenvalue problems sparse matrix-vector multiplication SpMV is of singular importance in sparse linear algebra. This policy decomposes a matrix multiply operation into CUDA blocks each spanning a 128-by-32 tile of the output matrix.
This policy is optimized for GEMM computations in which the C matrix. In the previous post weve discussed sparse matrix-vector multiplication. The thread block tiles storing A and B have size 128-by-8 and 8-by-32 respectively.
Examples of Cuda code 1 The dot product 2 Matrixvector multiplication 3 Sparse matrix multiplication 4 Global reduction Computing y ax y with a Serial Loop void saxpy_serialint n float alpha float x float y forint i 0. If you want to know how to use registers instead of shared memory then. In this paper we discuss data structures and algorithms for SpMV that are e ciently implemented on the CUDA platform for the ne-grained parallel architecture of the GPU.
Taking shared array to break the MAtrix in Tile widht and fatch them in that array per ele. Pd row WIDTH col Md row WIDTH k Nd k WIDTH col. 21 The CUDA Programming Model.
Further there is a matrix multiplication example in the CUDA SDKexamples and CUDA ships with CUBLAS. Implementing in CUDA We now turn to the subject of implementing matrix multiplication on a CUDA-enabled graphicscard. We will begin with a description of programming in CUDA then implement matrix mul-tiplication and then implement it in such a way that we take advantage of the faster sharedmemory on the GPU.
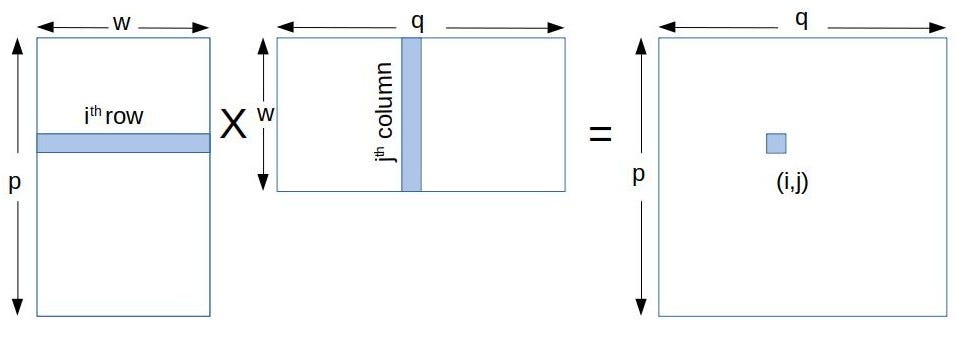
Matrix multiplication between a IxJ matrix d_M and JxK matrix d_N produces a matrix d_P with dimensions IxK.

A Vector Matrix Multiplication In An Lstm Gate B Gpu Computation Download Scientific Diagram
Cuda Matrix Vector Multiplication Transpose Kernel Cu At Master Uysalere Cuda Matrix Vector Multiplication Github
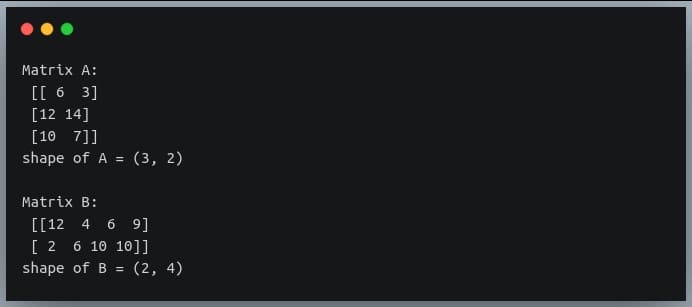
20 Examples For Numpy Matrix Multiplication Like Geeks

Matrix Multiplication Background User Guide Nvidia Deep Learning Performance Documentation
Matrix Multiplication In Cuda A Simple Guide By Charitha Saumya Analytics Vidhya Medium

Matrix And Vector Multiplication Programmer Sought
Solved Multiply Vectors By Matrix In Gpu Ni Community


Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow
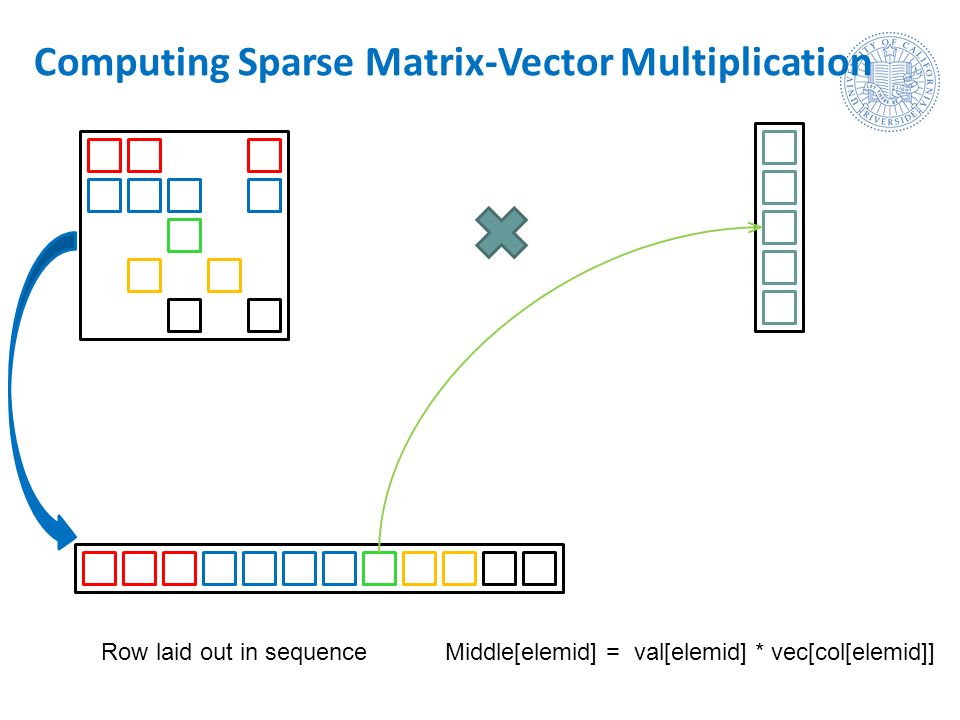
Irregular Applications Sparse Matrix Vector Multiplication Ppt Video Online Download

Support Vector Machine Svm Formulation And Matrix Vector Download Scientific Diagram
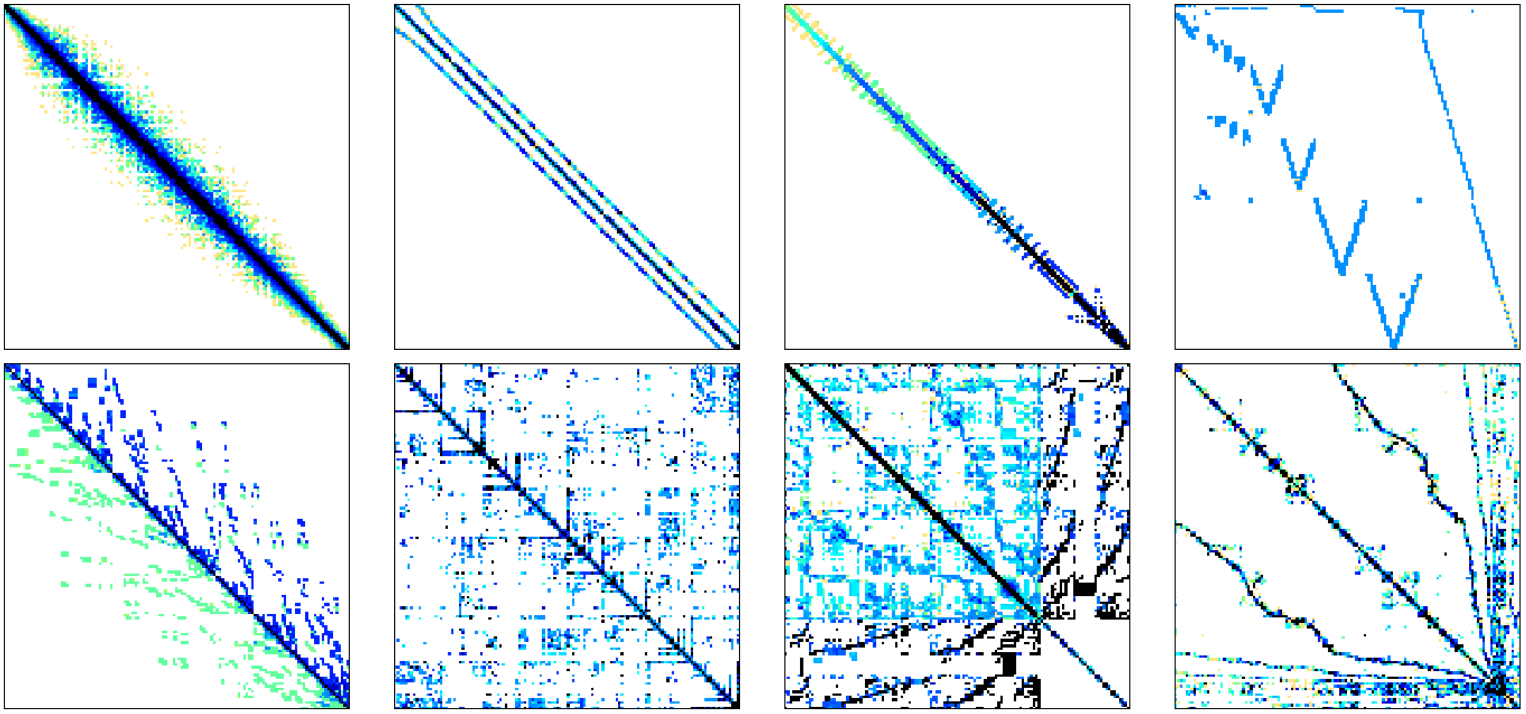
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow
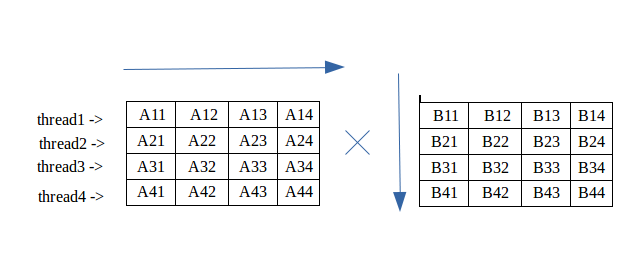
Multiplication Of Matrix Using Threads Geeksforgeeks
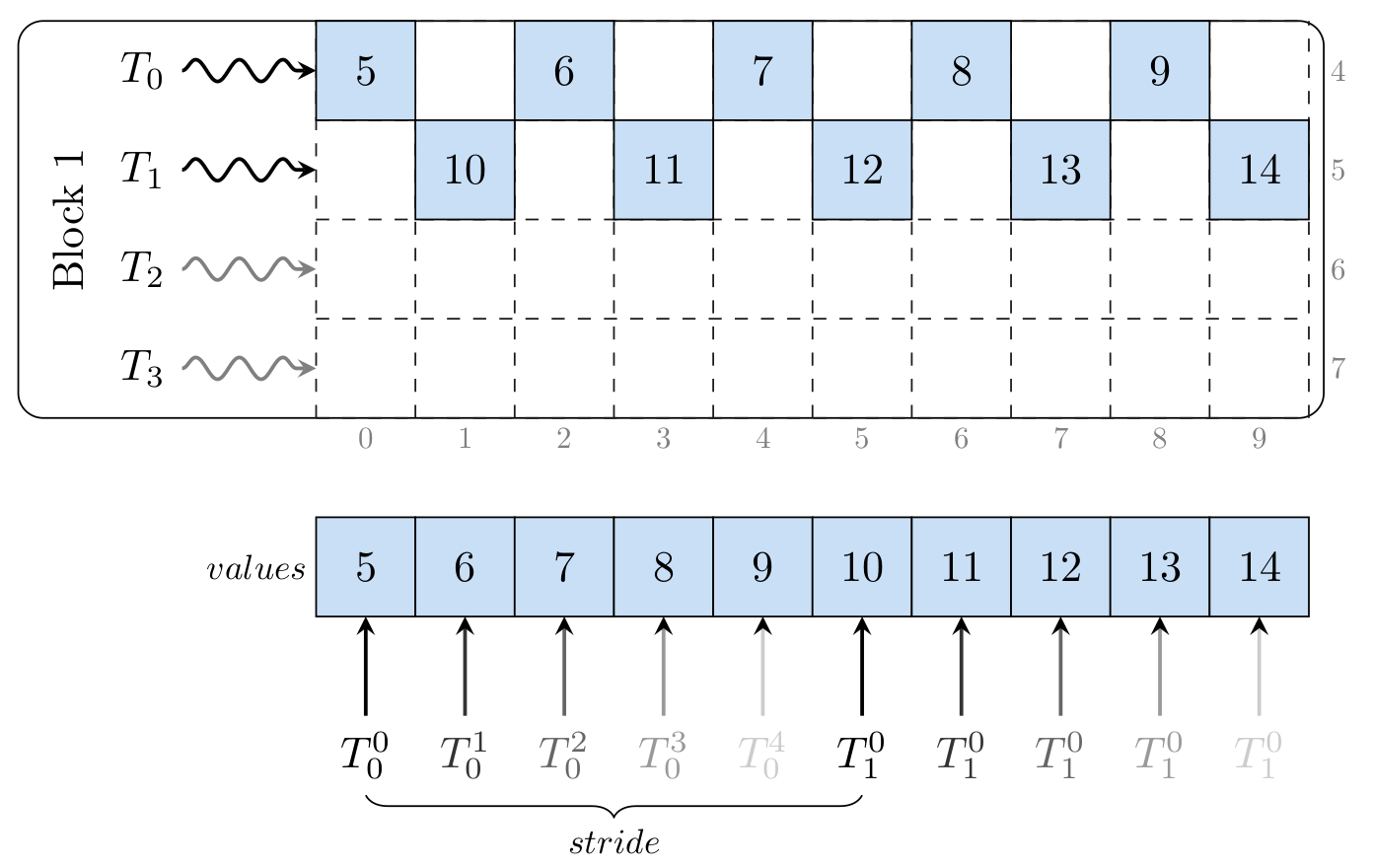
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Simple Matrix Multiplication In Cuda Youtube

6 Linear Algebra Representation Of The Sparse Matrix Vector Download Scientific Diagram
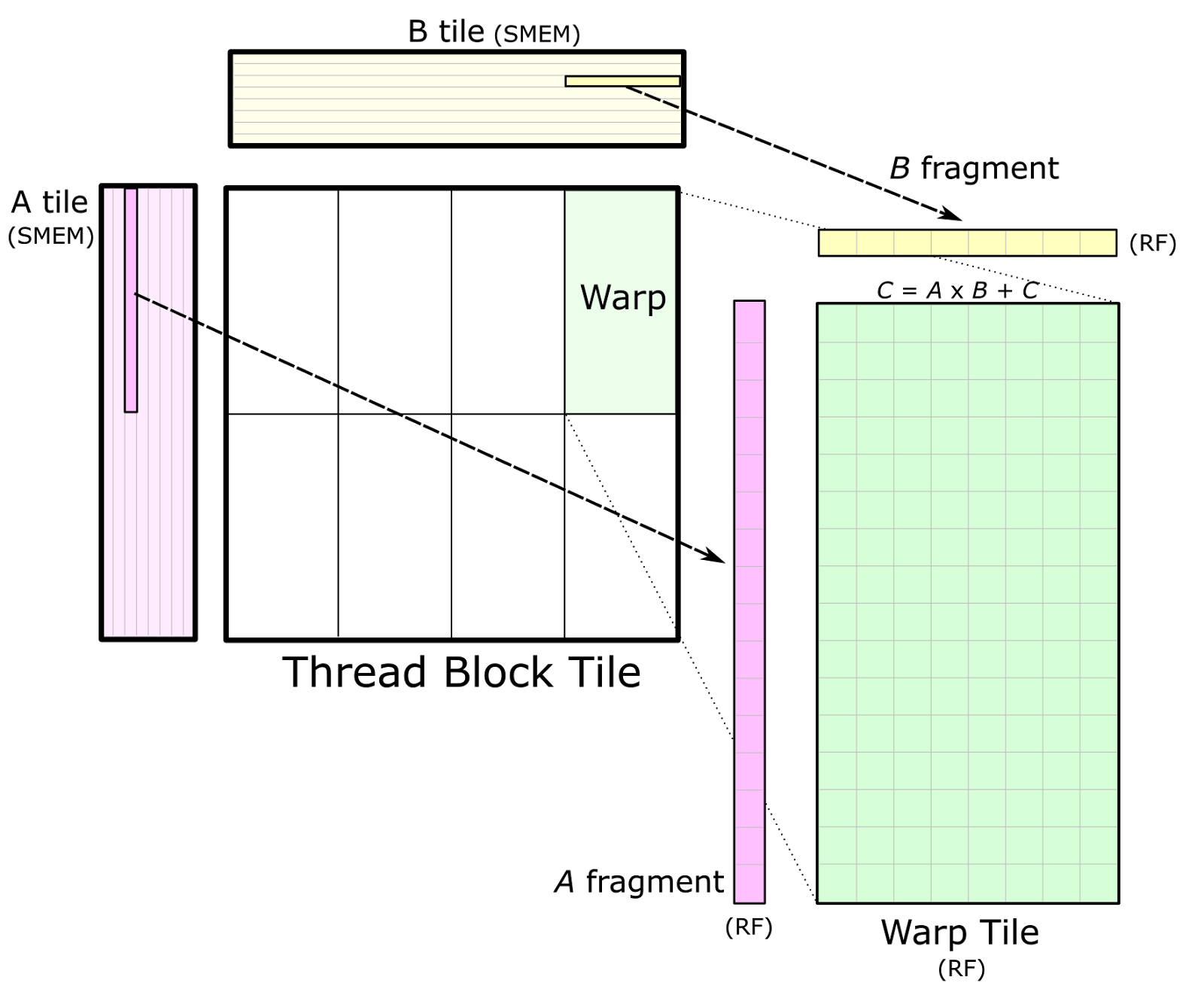
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog

Hierarchical Matrix Operations On Gpus Matrix Vector Multiplication And Compression

Pin On Useful Links